Life of a Request
High Level architecture
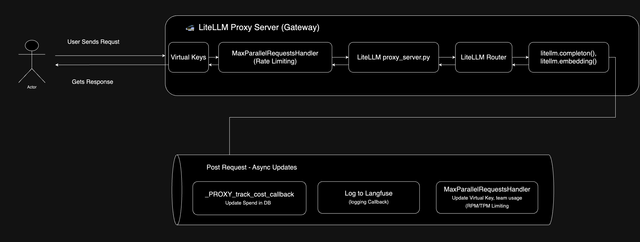
Request Flow
User Sends Request: The process begins when a user sends a request to the LiteLLM Proxy Server (Gateway).
Virtual Keys: At this stage the
Bearertoken in the request is checked to ensure it is valid and under it's budget. Here is the list of checks that run for each requestRate Limiting: The MaxParallelRequestsHandler checks the rate limit (rpm/tpm) for the the following components:
- Global Server Rate Limit
- Virtual Key Rate Limit
- User Rate Limit
- Team Limit
LiteLLM
proxy_server.py: Contains the/chat/completionsand/embeddingsendpoints. Requests to these endpoints are sent through the LiteLLM RouterLiteLLM Router: The LiteLLM Router handles Load balancing, Fallbacks, Retries for LLM API deployments.
litellm.completion() / litellm.embedding(): The litellm Python SDK is used to call the LLM in the OpenAI API format (Translation and parameter mapping)
Post-Request Processing: After the response is sent back to the client, the following asynchronous tasks are performed:
- Logging to LangFuse (logging destination is configurable)
- The MaxParallelRequestsHandler updates the rpm/tpm usage for the
- Global Server Rate Limit
- Virtual Key Rate Limit
- User Rate Limit
- Team Limit
- The
_PROXY_track_cost_callbackupdates spend / usage in the LiteLLM database. Here is everything tracked in the DB per request